Question 37
Which of the following options is correct regarding the below Object Repository tree structure?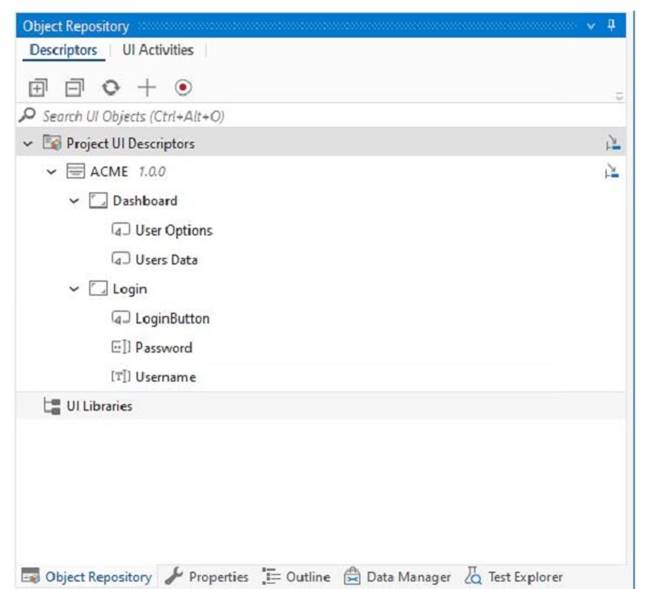
Correct Answer:D
The Object Repository tree structure shows one application with two screens and five UI elements. The application is the top-level node, the screens are the second-level nodes, and the UI elements are the third-level nodes. The UI elements have properties, selectors, and images that define them.
https://docs.uipath.com/studio/docs/about-the-object-repository
Question 38
A developer wants to extract hidden text from a pdf file. Which output method(s) should be used?
Correct Answer:D
To extract hidden text from a pdf file, the output method that should be used is FullText only. The FullText output method is one of the options available in the Read PDF Text activity, which reads all the characters from a specified pdf file and stores them in a string variable3. The FullText output method extracts the text from the pdf file as it is, without keeping the formatting or the position of the text. The FullText output method can also extract the hidden text from the pdf file, which is the text that is not visible on the screen, but can be copied and pasted into another application4. For example, the hidden text can be the metadata, comments, or annotations of the pdf file. The FullText output method is suitable for extracting hidden text from a pdf file, as it does not depend on the visibility or the layout of the text. The other output methods, such as Native or OCR, are not suitable for extracting hidden text from a pdf file, as they rely on the appearance or the position of the text on the screen. The Native output method preserves the formatting and the position of the text, but it cannot extract the text that is not visible or selectable5. The OCR output method converts the text from the pdf file into an image and then extracts the text from the image, but it cannot extract the text that is not displayed or recognized by the OCR engine6.
References: Read PDF Text, Extracting Hidden Text from PDF, Native, and OCR from UiPath documentation and forum.
Question 39
What is the purpose of credential stores in UiPath Orchestrator?
Correct Answer:C
Credential stores in UiPath Orchestrator are used to securely store sensitive information like Robot credentials and Credential Assets, which are essential for executing automated processes that require login details or other secure data. Orchestrator supports multiple credential stores at the tenant level and provides built-in support for secure stores such as CyberArk and Azure Key Vault. It also allows for the development of plugins for other secure stores if needed. (Orchestrator - Credential Stores - UiPath Academy) References:
✑ Orchestrator - Credential Stores - UiPath Documentation Portal
✑ Credential Stores - UiPath Orchestrator
Question 40
Which Scraping method should be used for the Get Text activity to capture hidden text from an application?
Correct Answer:D
The Get Text activity is used to extract the text value of a specified UI element. It does not use any of the scraping methods by default, but it can be configured to use the Full Text method in the Properties panel. The Full Text method is able to capture hidden text from an application, as well as the entire visible text and editable text. The Full Text method uses an internal OCR engine that works with most applications and languages.
References:
✑ Get Text activity documentation from UiPath
✑ Screen Scraping Methods documentation from UiPath
✑ Text scrapping forum post from UiPath Community
✑ How to: Scrape the Whole Text, Including Hidden Elements from a Terminal Window article from UiPath Knowledge Base
Question 41
The Extract PDF Page Range activity is used to extract a specific set of pages from a PDF file. Which of the following statements correctly describes this activity?
Correct Answer:B
The Extract PDF Page Range activity is used to extract a specific set of pages from a PDF file and save them as a new PDF file1. The OutputFileName argument is required and specifies the path and name of the new PDF file1. The Range argument accepts complex range values or “All” to indicate which pages to extract12. For example, “1-3,5,7-9” will extract pages 1 to 3, 5, and 7 to 92. The PageCount argument outputs the number of pages in the original PDF file, not the extracted pages1. Password-protected PDF files can be processed with this activity by using the Password argument to provide the password1.
References: Extract PDF Page Range documentation, Extract PDF Page Range example.
Question 42
When encountering an ApplicationException, what occurs if the developer chooses InvalidOperationException as the exception handler within the Catches section of the Try Catch activity?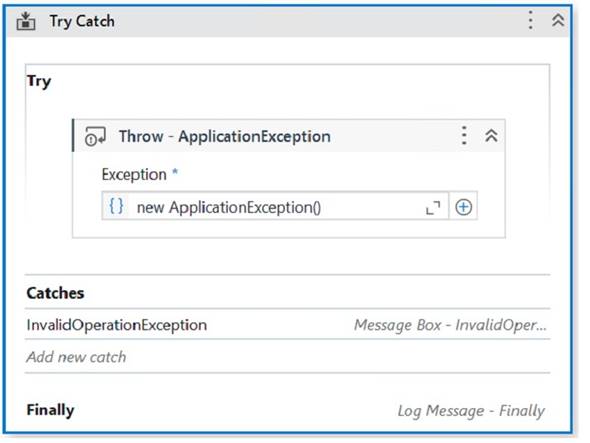
Correct Answer:B
The Try Catch activity is used to handle errors and exceptions that may occur during the execution of a workflow1. It has three sections: Try, Catches, and Finally1.
✑ The Try section contains the activities that may throw an exception or an error. If
an exception or an error occurs, the execution of the Try section is stopped and the control is passed to the Catches section1.
✑ The Catches section contains one or more exception handlers that specify what
type of exception or error to catch and what actions to perform when it is caught. The exception handlers are executed in order, from top to bottom, until a matching exception or error is found. If no matching exception or error is found, the execution of the workflow is stopped and a runtime error is thrown1.
✑ The Finally section contains the activities that are always executed at the end of
the Try Catch activity, regardless of whether an exception or error occurred or not. The Finally section is used to perform cleanup actions, such as closing applications, releasing resources, or logging messages1.
In your case, you have configured the properties for the Try Catch activity as follows:
✑ The Try section contains a Throw activity with an ApplicationException.
✑ The Catches section contains an InvalidOperationException with a Message Box activity and a Log Message activity.
✑ The Finally section is empty.
This means that the Try Catch activity will throw an ApplicationException in the Try section and look for a matching exception handler in the Catches section. However, since you have chosen InvalidOperationException as the exception handler, which does not match the ApplicationException, the execution of the workflow will be stopped and a runtime error will occur. The Finally section will not be executed.
Therefore, option B is correct.
References: Try Catch - UiPath Documentation Portal.