Online DP-600 Practice TestMore Microsoft Products >
Free Microsoft DP-600 Exam Dumps Questions
Microsoft DP-600: Implementing Analytics Solutions Using Microsoft Fabric
- Get instant access to DP-600 practice exam questions
- Get ready to pass the Implementing Analytics Solutions Using Microsoft Fabric exam right now using our Microsoft DP-600 exam package, which includes Microsoft DP-600 practice test plus an Microsoft DP-600 Exam Simulator.
- The best online DP-600 exam study material and preparation tool is here.
Question 1
- (Topic 2)
You have a semantic model named Model 1. Model 1 contains five tables that all use Import mode. Model1 contains a dynamic row-level security (RLS) role named HR. The HR role filters employee data so that HR managers only see the data of the department to which they are assigned.
You publish Model1 to a Fabric tenant and configure RLS role membership. You share the model and related reports to users.
An HR manager reports that the data they see in a report is incomplete. What should you do to validate the data seen by the HR Manager?
Correct Answer:B
To validate the data seen by the HR manager, you should use the 'Test as role' feature in Power BI service. This allows you to see the data exactly as it would appear for the HR role, considering the dynamic RLS setup. Here is how you would proceed:
✑ Navigate to the Power BI service and locate Model1.
✑ Access the dataset settings for Model1.
✑ Find the security/RLS settings where you configured the roles.
✑ Use the 'Test as role' feature to simulate the report viewing experience as the HR role.
✑ Review the data and the filters applied to ensure that the RLS is functioning
correctly.
✑ If discrepancies are found, adjust the RLS expressions or the role membership as needed.
References: The 'Test as role' feature and its use for validating RLS in Power BI is covered in the Power BI documentation available on Microsoft's official documentation.
Question 2
- (Topic 2)
You have an Azure Repos Git repository named Repo1 and a Fabric-enabled Microsoft Power Bl Premium capacity. The capacity contains two workspaces named Workspace! and Workspace2. Git integration is enabled at the workspace level.
You plan to use Microsoft Power Bl Desktop and Workspace! to make version-controlled changes to a semantic model stored in Repo1. The changes will be built and deployed lo Workspace2 by using Azure Pipelines.
You need to ensure that report and semantic model definitions are saved as individual text files in a folder hierarchy. The solution must minimize development and maintenance effort.
In which file format should you save the changes?
Correct Answer:C
When working with Power BI Desktop and Git integration for version control, report and semantic model definitions should be saved in the PBIX format. PBIX is the Power BI Desktop file format that contains definitions for reports, data models, and queries, and it can be easily saved and tracked in a version-controlled environment. The solution should minimize development and maintenance effort, and saving in PBIX format allows for the easiest transition from development to deployment, especially when using Azure Pipelines for CI/CD (continuous integration/continuous deployment) practices.
References: The use of PBIX files with Power BI Desktop and Azure Repos for version control is discussed in Microsoft’s official Power BI documentation, particularly in the sections covering Power BI Desktop files and Azure DevOps integration.
Question 3
- (Topic 2)
You have a Microsoft Fabric tenant that contains a dataflow. You are exploring a new semantic model.
From Power Query, you need to view column information as shown in the following exhibit.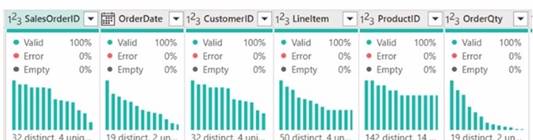
Which three Data view options should you select? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
Correct Answer:ABE
To view column information like the one shown in the exhibit in Power Query, you need to select the options that enable profiling and display quality and distribution details. These are: A. Enable column profile - This option turns on profiling for each column, showing statistics such as distinct and unique values. B. Show column quality details - It displays the column quality bar on top of each column showing the percentage of valid, error, and empty values. E. Show column value distribution - It enables the histogram display of value distribution for each column, which visualizes how often each value occurs.
References: These features and their descriptions are typically found in the Power Query documentation, under the section for data profiling and quality features.
Question 4
HOTSPOT - (Topic 2)
You have a data warehouse that contains a table named Stage. Customers. Stage- Customers contains all the customer record updates from a customer relationship management (CRM) system. There can be multiple updates per customer
You need to write a T-SQL query that will return the customer ID, name, postal code, and the last updated time of the most recent row for each customer ID.
How should you complete the code? To answer, select the appropriate options in the answer area,
NOTE Each correct selection is worth one point.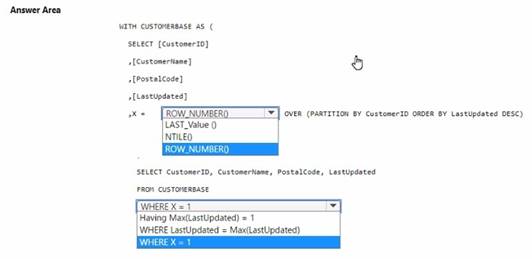
Solution:
✑ In the ROW_NUMBER() function, choose OVER (PARTITION BY CustomerID ORDER BY LastUpdated DESC).
✑ In the WHERE clause, choose WHERE X = 1.
To select the most recent row for each customer ID, you use the ROW_NUMBER() window function partitioned by CustomerID and ordered by LastUpdated in descending order. This will assign a row number of 1 to the most recent update for each customer. By selecting rows where the row number (X) is 1, you get the latest update per customer. References =
✑ Use the OVER clause to aggregate data per partition
✑ Use window functions
Does this meet the goal?
Correct Answer:A
Question 5
- (Topic 2)
You are analyzing the data in a Fabric notebook.
You have a Spark DataFrame assigned to a variable named df.
You need to use the Chart view in the notebook to explore the data manually. Which function should you run to make the data available in the Chart view?
Correct Answer:D
The display function is the correct choice to make the data available in the Chart view within a Fabric notebook. This function is used to visualize Spark DataFrames in various formats including charts and graphs directly within the notebook environment. References = Further explanation of the display function can be found in the official documentation on Azure Synapse Analytics notebooks.
Question 6
- (Topic 2)
You have a Fabric tenant that contains a workspace named Workspace^ Workspacel is assigned to a Fabric capacity.
You need to recommend a solution to provide users with the ability to create and publish custom Direct Lake semantic models by using external tools. The solution must follow the principle of least privilege.
Which three actions in the Fabric Admin portal should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
Correct Answer:ACD
For users to create and publish custom Direct Lake semantic models using external tools, following the principle of least privilege, the actions to be included are
enabling XMLA Endpoints (A), editing data models in Power BI service (C), and setting XMLA Endpoint to Read-Write in the capacity settings (D). References = More information can be found in the Admin portal of the Power BI service documentation, detailing tenant and capacity settings.