Online DP-500 Practice TestMore Microsoft Products >
Free Microsoft DP-500 Exam Dumps Questions
Microsoft DP-500: Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI
- Get instant access to DP-500 practice exam questions
- Get ready to pass the Designing and Implementing Enterprise-Scale Analytics Solutions Using Microsoft Azure and Microsoft Power BI exam right now using our Microsoft DP-500 exam package, which includes Microsoft DP-500 practice test plus an Microsoft DP-500 Exam Simulator.
- The best online DP-500 exam study material and preparation tool is here.
Question 1
- (Exam Topic 3)
You have an Azure Synapse workspace named Workspace1.
You need to use PySpark in a notebook to read data from a SQL pool as an Apache Spark DataFrame and display the top five
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Solution:
Does this meet the goal?
Correct Answer:A
Question 2
- (Exam Topic 3)
You are creating a Power 81 single-page report.
Some users will navigate the report by using a keyboard, and some users will navigate the report by using a screen reader.
You need to ensure that the users can consume content on a report page in a logical order. What should you configure on the report page?
Correct Answer:B
Question 3
- (Exam Topic 3)
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly specify the maximum length for businessName and surveyName.
Does this meet the goal?
Correct Answer:B
Question 4
- (Exam Topic 3)
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that the SQL pool is scanned by Azure Purview. What should you do first?
Correct Answer:B
Question 5
- (Exam Topic 3)
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly define the collation for businessName and surveyName as Latim_Generai_100_BiN2_UTF8.
Does this meet the goal?
Correct Answer:A
Question 6
- (Exam Topic 1)
You need to populate the CustomersWithProductScore table.
How should you complete the stored procedure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.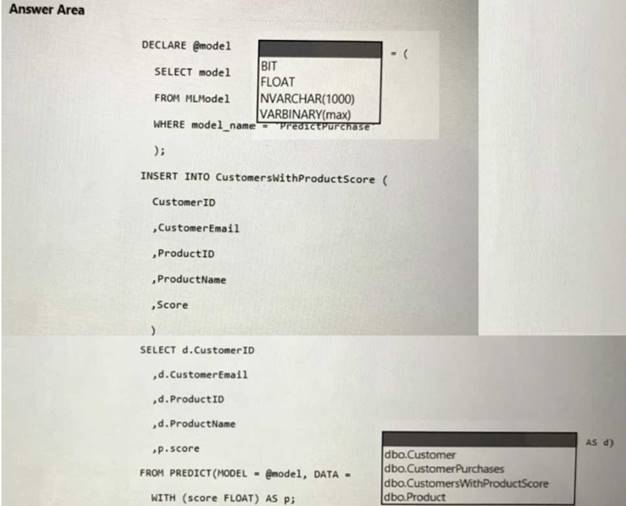
Solution: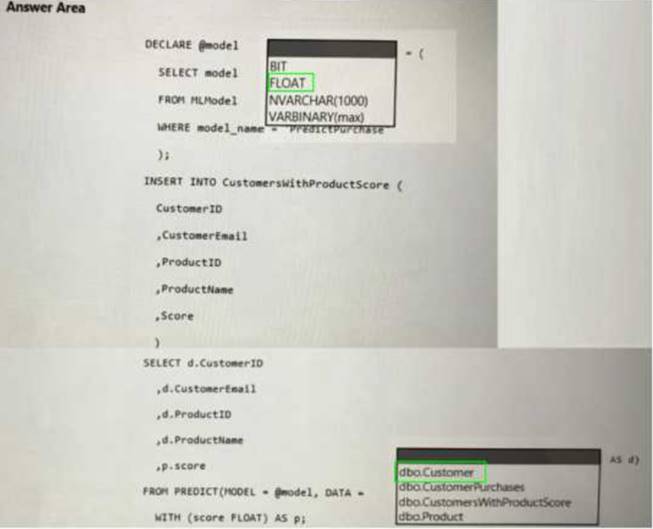
Does this meet the goal?
Correct Answer:A